(disclosure- I am involved with and invested in Lumesis, which sells Muni credit & compliance software)
 So Detroit filed for bankruptcy last week.
So Detroit filed for bankruptcy last week.
If you live in the US and don’t work in municipal finance, you probably barely registered this news.
And you probably think that it’s not that surprising that something bad happened in Detroit. I mean, during the recession a house there cost less than a car. So we all saw this coming, right?
Well, yes and no.
Yes, everyone in the muni market knew that Detroit was a poor credit. It’s not a surprise- that’s not why it’s a big deal.
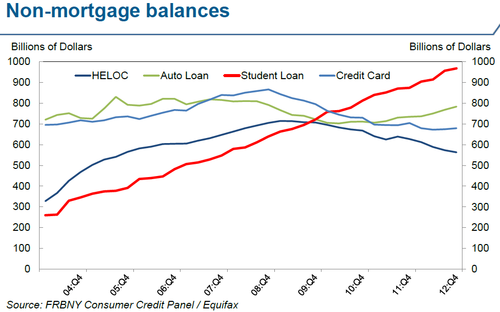
The default is by far the largest ever for a municipality, as the Times can show you:

$18 billion (or more) is nothing to sneeze at, but in the context of the $600 billion pension underfunding and the $3 trillion muni market, it’s minor. This will hurt a few investors badly (including my old coworkers at Ambac), but that’s not why this is a big deal.
Detroit’s (modest) pensions put about $3 billion of payments to retirees at risk. It is very possible that thousands of pension-holders will lose a substantial part of their future income and be plunged into poverty. It’s horrible, but that’s not why this is a big deal.
Detroit’s bankruptcy filing is a big deal because it marks a fundamental change in the relationship between cities and those who finance their projects.

Imagine being a city (or county, or state) administrator. You collect taxes and pay your police and firefighters. You have inherited a pension fund from the previous administrator, and you are legally obligated to fund it. And you raise money from the bond market (and others) to finance projects like building a new school or a new road, and you pay the bondholders back over a decade or more.
Imagine that, suddenly, you lose a bunch of revenue. Maybe there’s an exodus of people, reducing your income and sales tax collections. Maybe real estate price drops decimate your property tax base. Maybe the Federal Government reduced payments you depended on? Or maybe you (or the last administrator) spent recklessly or was corrupt or just invested in projects that didn’t work out. The reason doesn’t matter. You’re broke.
You have a bunch of options. You can ask for aid, though that gives others a lot of leverage over you. You can cut or freeze spending, though that makes your city less pleasant to live in, further decreasing property value. You can ask your workers to share the pain, but there’s only so far that will take you. And remember, those union members pay taxes and vote. You can stop funding your pension, but there’s only so long you can live on your credit.
And then there are your bondholders.
"I used to think if there was reincarnation, I wanted to come back as the president or the pope or a .400 baseball hitter. But now I want to come back as the bond market. You can intimidate everybody." –James Carville
Bondholders, in some respects, are the easiest stakeholders to push the losses to when things go bad. They have fewer votes than the union and won’t move out of your city if you default. The bondholders in your town may even be insured by a large company such as Ambac or Assured, so you might lose zero votes for declaring bankruptcy and sticking these insurers with the bill.
The bond market knows this and has a bunch of tools to handle this: securing bonds, reserve funds, credit support and seniority, to name a few. But the most powerful tool is known as market discipline.
Basically, you can think of market discipline in the bond market as tit-for-tat: if you don’t pay me now, I won’t lend you money in the future. Game theory 101. But it goes way beyond that.
Muni lenders and insurers have traditionally been able to put pressure on localities through their states. If Michigan let one city treat its bondholders poorly, bondholders will demand higher interest from every other city in Michigan looking to raise money, as well as the State itself. This way bondholders can leverage their status as a major source of the entire State’s financing.
This is what Carville is talking about when he says that the bond market is intimidating. States that have a reputation for being less friendly to bondholders (like California) pay higher interest rates than those with better reputations. This is also part of the reason that issuers look at different yield curves for each State. States are anxious to keep finance costs low for themselves and their communities, so they are usually ready to play ball with financers’ demands.
And THIS is what is important about Detroit. The fact the city doesn’t want to pay is no surprise. But the role of the State and Governor has been.
“Realistically, if you step back, if you were lending to the city of Detroit in the last few years, didn’t you understand there were major issues and problems?... Look at the yields they’re obtaining compared to other bonds. They were getting a premium.” - Michigan Governor Rick Snyder on Face the Nation
This. A prominent Republican Governor, (who has a finance background, no less) and is considered a 2016 presidential candidate, is going on national TV and basically saying that the bondholders had it coming. The State’s emergency manager has floated a plan that would give some bondholders about 10c on the dollar.
This is not playing ball. And this shift in attitude has been the primary concern of investors who have been shunning the market.
'When faced with large revenue shortfalls, communities that have all of their bonds insured will be more prone to develop “solutions” less favorable to bondholders than those communities that have uninsured bonds held by local banks and residents. Losses in the tax-exempt arena, when they come, are also likely to be highly correlated among issuers. If a few communities stiff their creditors and get away with it, the chance that others will follow in their footsteps will grow. What mayor or city council is going to choose pain to local citizens in the form of major tax increases over pain to a far-away bond insurer?' –Warren Buffett, 2009
This is bad news for everyone. Even if Detroit’s filing is rejected by the courts (a possibility) thousands of city and state administrators dealing with similar issues on a smaller scale will be following this. At the very least, trust between cities and lenders will fray, requiring investors to spend more time and money analyzing and monitoring their credits, which will push up costs. And higher borrowing costs can’t be good for already stressed budgets.
And if Detroit emerges in 2-3 years in better shape (and really, how much worse shape could it be in?) how strong will the temptation be to restructure, or at least use the threat of restructuring to obtain concessions from lenders?
If many more municipalities default in the future, it is likely to impact you in some way, whether your pension or a family member’s job or the services that your community is able to provide.
This won’t come soon. Nothing in the Muni market moves fast, and smarter people than I have looked bad predicting downturns. But I think that this, truly, is the opening round in a new era for the market.
 Late last year, I agreed to teach a master's course in data visualization at the City University of New York.
Late last year, I agreed to teach a master's course in data visualization at the City University of New York.




 I wrote a guest post on Chicago's finances for
I wrote a guest post on Chicago's finances for 





{kind=link}
{kind=link}